 meducode
meducode

- エクセルのデータをPythonで読み込む。
- Pythonでデータをグラフ化する。
ではPythonプログラミングをはじめましょう。

本サイトでは、データ分析をしながらPythonプログラミングを学習します。
とにかく「使って覚える」スタイルで進めます。
今回使用するのは、Pima Indians(ピマ・インディアン)の糖尿病に関するデータセットです。
Pima Indiansはアメリカのアリゾナ州に住むネイティブ・アメリカンであり、40歳以上の2/3は糖尿病に罹患しています。
本データは21歳以上の被験者(768名)の医療データと、糖尿病に罹患しているかどうかがまとめられています。
この記事をすべて実行したあとのGoogle Colabのデータは以下から閲覧できます。

では早速、データをダウンロードしましょう。
こちらからダウンロードしてください。エクセルファイル(diabetes.xlsx)がダウンロードされます。
もしダウンロードできない場合は、こちらからダウンロードしてください。
ここからダウンロードした場合は、以下の「CSVファイルに変換する」手順を飛ばしてください。
Googleドライブを開いてください。
なおGoogleドライブを利用するまでの手順は以下を参照してください。
 プログラミング学習用のGoogleアカウントをつくろう
プログラミング学習用のGoogleアカウントをつくろう  Google DriveとGoogle Colabを準備しよう
Google DriveとGoogle Colabを準備しよう Googleドライブ内に「Pythonによるデータ分析入門 > 初級編 > 000_データの読み込みとグラフ化」の順にフォルダを作成してください。
つまり「マイドライブ」フォルダの下に「Pythonによるデータ分析入門」をつくり、さらにその下に「初級編」、さらに下に「000_データの読み込みとグラフ化」という入れ子構造でフォルダを作成してください。
実際には好きなようにフォルダを作ってOKです。
ただし、のちのち「ここにあるファイルを使ってね」と説明するかもしれないので、同じフォルダ構成だと楽だと思います。
フォルダを作ると以下のような画面になります。
作成したフォルダにダウンロードしたdiabetes.xlsxファイルをアップロードしてください。

「どうやるの?!」と思ったみなさん、ごめんなさい
わざと細かい説明を省略しました。
「なるべく写真を増やしてわかりやすくしたい」と思っていますが、時間の経過とともに、写真が実際の画面と変わってしまう場合も多いのです。
プログラミングを学習する上で「多分こうやるんだろうな力」も重要です。
そのため、ちょっとイジワルな書き方をしました(すみません)。フォルダ作成の詳細は以下のとおりです。
「新しいフォルダ」を選択し、フォルダ名を入力してください。
もしフォルダ名を間違えても、「フォルダを選択して右クリック」メニューから「名前を変更」とすればOKです。
この手順で、まずは「Pythonによるデータ分析入門」フォルダを作り、フォルダ名をダブルクリックして当該フォルダ内に入ります。そしてもう一度「新規」から「初級編」フォルダを作成……と繰り返してください。
“_“(アンダースコア)の入力方法が分からないときは、本文からコピペすればOKです。
diabetes.xlsx ファイルをGoogleドライブにアップロードします。
ドラッグ・アンド・ドロップで行うのが簡単ですが、メニューの「新規」から「ファイルをアップロード」を選択してもOKです。

以上で、新規フォルダを作成して、ファイルをアップロードするまでの手順は完了です。
ここまででdiabetes.xlsxファイルのアップロードは完了です。
つぎにファイルを選択して右クリックから「アプリで開く > Googleスプレッドシート」を押してください。
Googleスプレッドシートは、Googleが提供しているExcelのようなものです。
Microsoft Excel ほど高機能ではありませんが、十分に活用できます。
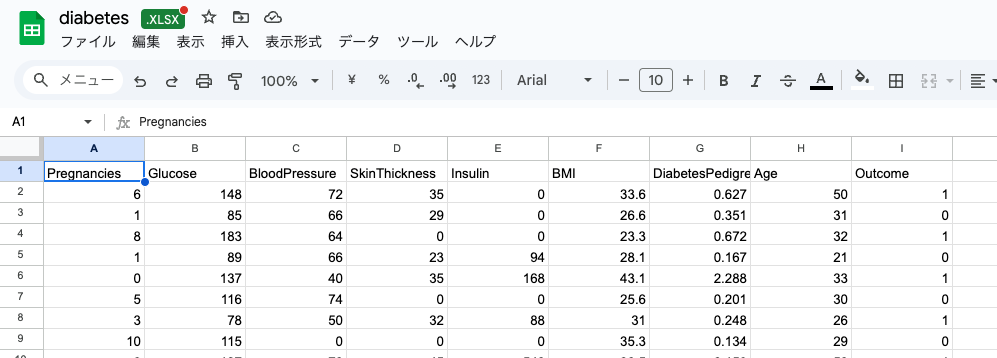
これが今回使用するPima Indians Diabetes Databaseの内容です。
「こんなことしないで、単にエクセルで開けばいい」という意見は、そのとおりです。
本記事は「パソコンにエクセルがなくても大丈夫」という意図で作成しています。

ここが意外と忘れ去られるポイントです!!
まずはデータの全体像をざっと見ましょう。
プログラミングやBIツールでデータ分析をするときに意外と忘れられてしまうのが「自分でデータの全体像を見る」ことです(「BIツール」とはBuiness Intelligenceツールのことで企業が保有するデータを解析し、意思決定するためのツール群を指します)。
「どれくらいの数字が並んでいるのか」、「欠損値はないか」、「数字の中に文字が混ざっていないか」などをざっと見ましょう。総じていえば「どんなデータなのか」をなんとなく把握するとよいでしょう。
列(縦)を見ると、「Pregnancies(妊娠回数)」、「Glucose(血糖値)」、「BloodPressure(血圧)」、「SkinThickness(皮膚の厚さ)」、「Insulin(インスリン濃度)」、「BMI」、「DiabetesPedigreeFunction(糖尿病血糖要因)」、「Age(年齢)」、「Outcome(結果)」の合計9列あることがわかりました。

これらの項目と糖尿病の関連について補足します(エクセルデータからでは分からない部分を含みます)。
Pregnancies:妊娠回数。妊娠回数が増えると、妊娠糖尿病のリスクが上昇します。
Glucose:経口ブドウ糖負荷試験(Oral Glucose Tolerance Test, OGTT)から2時間後の血漿中のグルコース濃度。OGTT
から2時間も経つと、健常者ではグルコース濃度は下がっています。
BloodPressure:血圧。高血圧と糖尿病には相関があります。
SkinThickness:皮膚の厚さ。皮下脂肪の量を示し、体脂肪率との相関を示します。
Insulin:OGTTから2時間後の血清インスリン濃度。インスリン抵抗性があると血糖値が高いまま維持されます。
BMI:Body Mass Index. 肥満傾向かどうかの指標です。
DiabetesPedgreeFunction:糖尿病血糖要因、糖尿病家系機能。糖尿病の家族歴と遺伝的要因を数値化した指標です。
Age:年齢。加齢に伴いインスリン分泌量が減少します。
もともとはdiabetes.xlsxというファイル形式でしたが、これをdiabetes.csvというファイル形式に変換します。
このドット”.“以降の部分を「拡張子(extension, エクステンション)」と言います。
csvは、表形式データ(行列データ)を保存するために用いられる一般的な拡張子です。プログラミングでは.xlsxはあまり扱わず、.csvを使うことがほとんどです。
csvファイルにすると大体のパソコンで処理できるので、こちらが使われています。
例えば、xlsxという拡張子はMicrosoft Excelと紐づいており、docxはMicrosoft Wordですよね。
同じようにcsvはテキストエディタと結びついています。テキストエディタというのは、Windows標準の「メモ」アプリ(Macではテキストエディット)であり、ほとんどのパソコンにインストールされている最も単純なアプリです。
なお、csvはComma Separeted Valueの略であり、エクセルの「セル」に相当するものをカンマ区切りで表現しています。
例えば、Pregnancies, Glucose, BloodPressureと書くとセルが3つ横に並んでいることを意味します。
Googleスプレッドシート画面に戻ってください。
「ファイル > ダウンロード > カンマ区切り形式」を選択してください。
するとあなたのパソコンにdiabetes.csvファイルがダウンロードされます。
ダウンロードしたdiabetes.csvファイルをGoogleドライブにアップロードしてください(diabetes.xlsxファイルと同じ階層でOKです)。

xlsxからcsvへの変換は、Google SpreadSheetではなくMicrosoft Excelでも可能です。
アップロードが完了すると上記のような画面になります。
Googleドライブにdiabetes.xlsx(もとのファイル)とdiabetes.csv(変換後のファイル)の2つが保存されています。
ではGoogle Colabに画面を戻してください。
画面を行ったり来たり大変だな、と思った方は以下の記事を参考にしてください。
 ウェブブラウザの分割表示でプログラミング学習を効率化しよう
ウェブブラウザの分割表示でプログラミング学習を効率化しよう 「ファイル > ドライブの新しいノートブック」を選択してください。
画面の切り替えに少し時間がかかりますが、新しい画面が表示されます。
「Untitiled0.ipynb」と表示されていますね。
これは、Untitled0(= 無題0)というファイル名のノートブックです。
.ipynbという拡張子は、ノートブックのための拡張子です。
.ipynbは、「Interactive PythonのNotebookだよ」という意味です。
Google Colabは、そもそもIPyhon(対話型Python)という機能を使っているので、ノートブックは.ipynbという拡張子を使っているわけですね。
ノートブックを新しく作ると、Untitiled(無題)というファイル名が自動的につきます。
わかりにくいので、きちんと名前をつけましょう。
ファイル名のところにカーソルを持っていき、クリックすると編集できるようになります。
もしくは「ファイル > 名前の変更」を選択してください。
ファイル名を「000_import-data」としてください。

繰り返しになりますが、実際にはファイル名は何でもOKです。
本ブログと同じにしておくと「分かりやすい」ってだけです。
先ほど、Googleドライブ内に「Pythonによるデータ分析入門 > 初級編 > 000_データの読み込みとグラフ化」という順序でフォルダを作りました。
ノートブックもここに保存しましょう。
「ファイル > 移動」を選択してください。
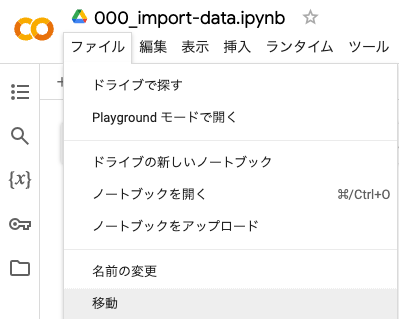
すると下記のようにポップアップウィンドウが表示されるので、「Colab Notebooks」の前にある矢印をクリックしてください。

すると、以下のように切り替わります。

フォルダの階層が上に行ったわけですね。今は「マイドライブ」フォルダの中身が見えている状態です。

作成した「Pythonによるデータ分析入門 > 初級編 > 000_データの読み込みとグラフ化」という順番でフォルダの階層を下りていきます。


目的のフォルダである「000_データの読み込みとグラフ化」まで来たら「フォルダを選択」を押してください。

これで、000_import-data.ipynbファイルが、「000_データの読み込みとグラフ化」フォルダに移動しました。
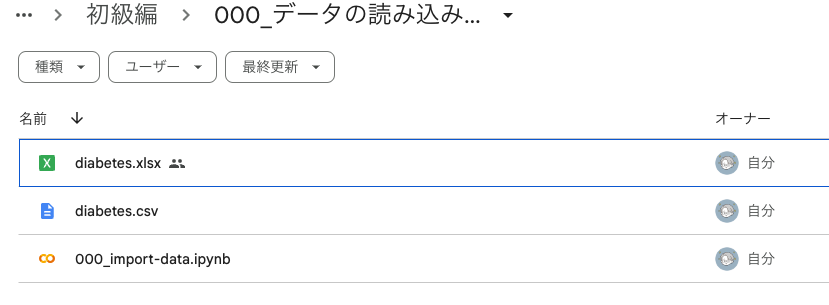
この状態でGoogleドライブを確認してみると、上のように見えます。
確かに000_import-data.ipynbファイルが保存されていますね。
色々と細かい指示を出してきたので、ちょっとまとめますね
Googleドライブ(マイドライブ)には、現在の状態では2つのフォルダがあります。
「Pythonによるデータ分析入門」と「Colab Notebooks」です。なのでマイドライブには以下のような2つのフォルダが見えています。
もちろん人によっては、他のフォルダを作成している場合もありますが、本記事における指示に従うと以下の2つが見えるはずです。
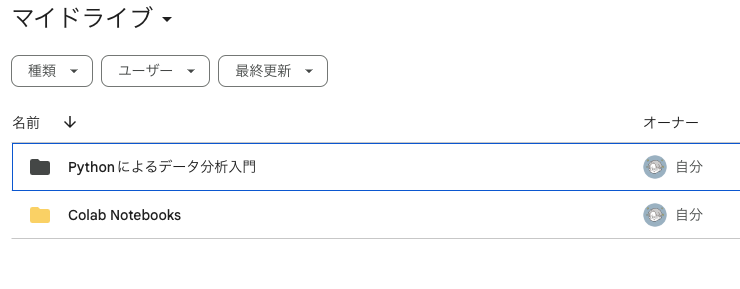
そして「Pythonによるデータ分析入門」をダブルクリックすると「初級編」フォルダが見えます。
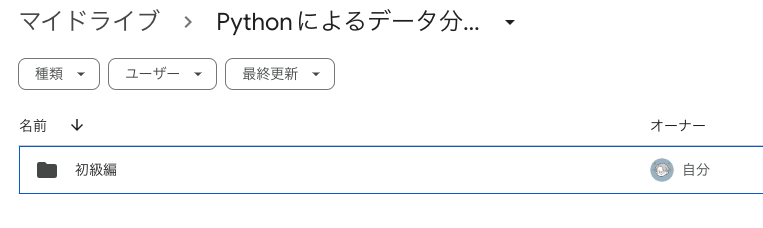
「初級編」フォルダをダブルクリックすると「000_データの読み込みとグラフ化」フォルダが見えます。
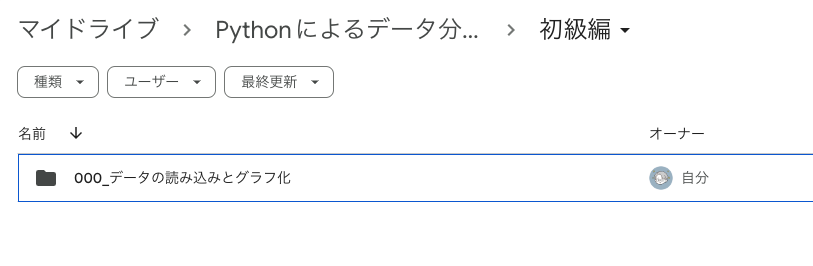
「000_データの読み込みとグラフ化」フォルダをダブルクリックすると、ようやくファイルが見えます。
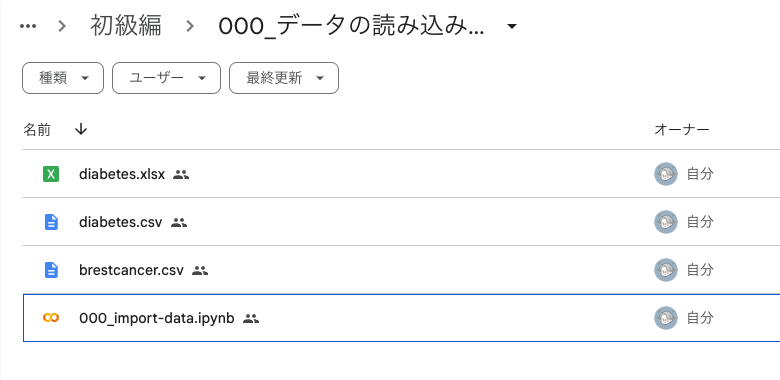
私の場合はbrestcancer.csvも見えていますが、本記事の指示に従うとdiabetes.xlsx, diabetes.csv, 000_import-data.ipynbという3つのファイルがあるはずです。
「フォルダ名やファイル名はコピペしてください」と指示をしていますが、どうしても「半角スペース」が紛れ込んでしまいます。
この半角スペースがクセモノなんです。それだけでエラーが出てしまうのです
演習でエラーが生じないように、フォルダもコードで作成するのもOKです。
以下のコードをGoogle Colabで実行すれば、ここまでのフォルダ構造等の設定を行うことができます。
from google.colab import drive
import os
import requests
# Googleドライブのマウント
drive.mount('/content/drive')
# フォルダの作成
folder_path = '/content/drive/MyDrive/Pythonによるデータ分析入門/初級編/000_データの読み込みとグラフ化'
os.makedirs(folder_path, exist_ok=True)
# CSVファイルのダウンロード
csv_url = 'https://drive.google.com/uc?id=1E4a--uFQSZVmyEEp06ojH3W-UfofkgS1'
csv_file_path = os.path.join(folder_path, 'diabetes.csv')
try: response = requests.get(csv_url) response.raise_for_status() # HTTPエラーが発生した場合に例外を発生させる with open(csv_file_path, 'wb') as f: f.write(response.content) print(f'CSVファイルを {csv_file_path} にダウンロードしました。')
except requests.exceptions.RequestException as e: print(f'CSVファイルのダウンロード中にエラーが発生しました: {e}')Google Colabの実行に関しては、以下の項目を参照してください。

Google Colabには生成AIが搭載されているので、コーディングも簡単です。
ノートブックのセルにある「コーディングを開始するか、AIで生成します」の「生成」をクリックしてください。
セル(Cell)というのは、以下の画像のようなノートブック上のブロックのことです。

「生成」をクリックすると、セルの形が変わります。
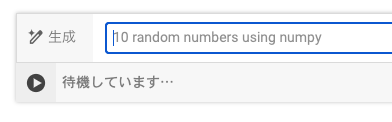
ここに「Googleドライブ内にあるcsvファイルを読み込んで、列名Aのデータでヒストグラムを作成してください」と入力してください(コピペしてくださいね)。
この入力文を「プロンプト(Prompt)」と言います。
すると、あっという間にコードが生成されます。
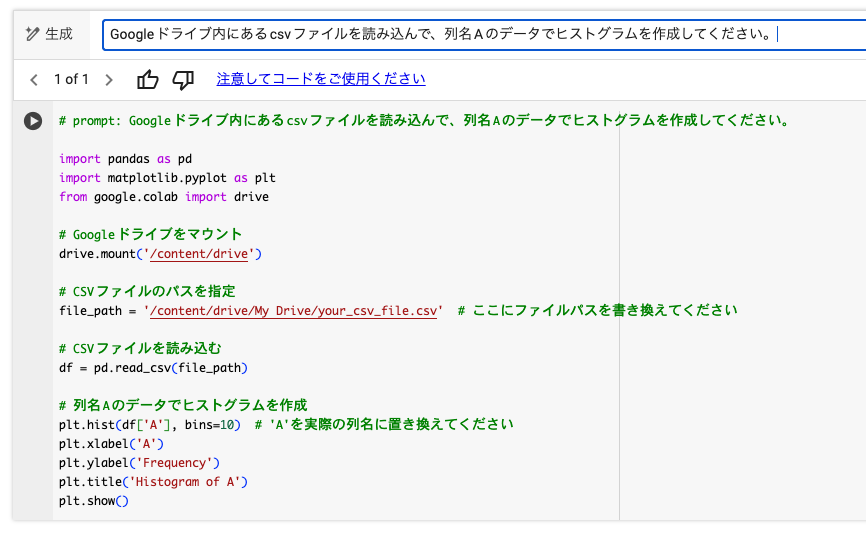
import pandas as pd
import matplotlib.pyplot as plt
from google.colab import drive
# Googleドライブをマウント
drive.mount('/content/drive')
# CSVファイルのパスを指定
file_path = '/content/drive/My Drive/your_csv_file.csv' # ここにファイルパスを書き換えてください
# CSVファイルを読み込む
df = pd.read_csv(file_path)
# 列Aのデータでヒストグラムを作成
plt.hist(df['A'], bins=10) # 'A'を実際の列名に置き換えてください
plt.xlabel('A')
plt.ylabel('Frequency')
plt.title('Histogram of A')
plt.show()プロンプトはもう必要ないので、右側の「閉じる」を押してください。

まずは試しにコードを実行してみましょう。
セルの左上にある再生ボタンのようなマークを押してください。
すると「Googleドライブのファイルへのアクセスを許可しますか?」というポップアップが表示されます。
「Googleドライブに接続」を選択してください。

新しいウィンドウが表示されます。
利用したいアカウントを選択してください。
さらに画面が遷移します。「次へ」を選択してください。
「Google Drive for desktopがアクセスできる情報を選択してください」と表示されます。
「すべてを選択」して「続行」してください。
そしてGoogle Colabの画面に戻ってください。
セルが実行された結果を見ることができます。
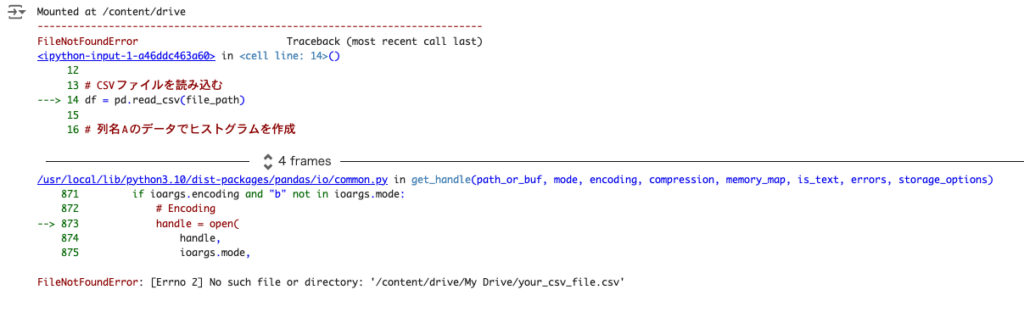
何やらエラーが発生していますね。
次はこのエラーを修正してみましょう。
ここまでの作業が結構長くなりましたね。ちょっと整理しましょう。
diabetes.xlsxをダウンロードしました。
diabetes.xlsxにどんなデータが記述されているのかをざっと確認しました。
Googleスプレッドシートを使って、.xlsxファイルを.csvファイルに変換しました。
生成AIを活用して、Google Colabからdiabetes.csvファイルを読み込むためのコードを書いてもらいました。
ただしエラーが発生しています。
いまココ!!
生成AIを使ってcsvファイルのデータを可視化する。
さてここまでの作業をまとめると、「Googleドライブ内のcsvファイルを読み込もうとしたらエラーが出た」という感じですね。
でもここもAIに助けてもらいましょう。「エラーの説明」をクリックしてください。
すると以下のように、解説文が表示されます。
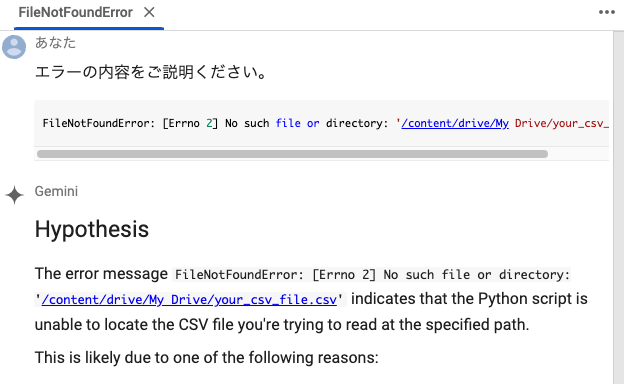
英語でわかりにくいので、日本語で解説してもらいましょう。
プロンプト入力部分に「日本語で解説してください」と入力してください。

すると以下のように、日本語で解説してくれます。

すごいですね
解説を読むと「ファイルパスが間違っている」という指摘を受けました。
コードでは、/content/drive/My Drive/your_csv_file.csvを読み込むことが書かれているのに、「そこにcsvファイルがないよ」というエラーのようですね。
では、正しく修正してもらいましょう。
diabetes.csvファイルは、「Pythonによるデータ分析入門 > 初級編 > 000_データの読み込みとグラフ化」フォルダにあるんでしたね。その旨をAIに伝えてみましょう。
修正してほしい内容をそのままAIに伝えてあげればOKです
プロンプトに「マイドライブ > Pythonによるデータ分析入門 > 初級編 > 000_データの読み込みとグラフ化 > diabetes.csv を読み込むようにコードを修正して下さい」と入力しましょう。
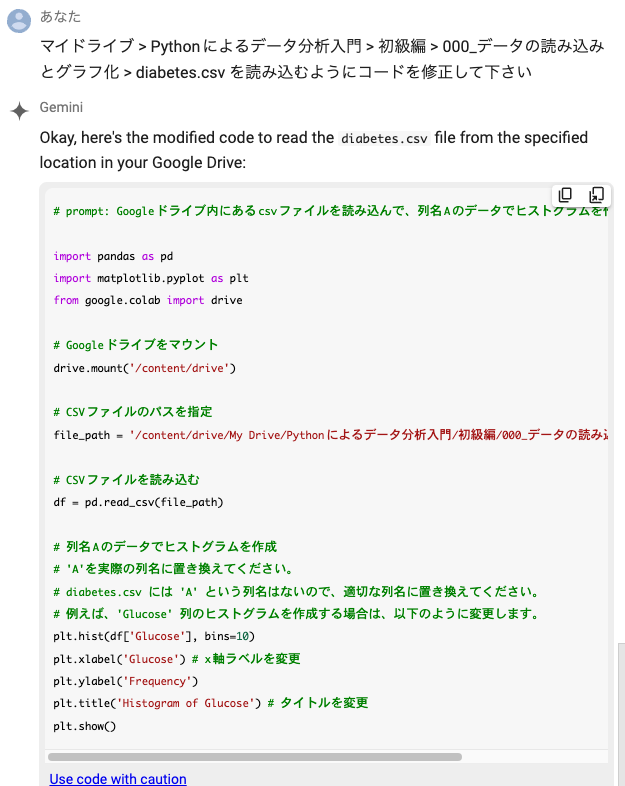
上記のようにコードが修正されました。
しかも賢いことに、「列名Aがないから、Glucoseにしてみたよ」という修正まで勝手にやってくれています。

AIが作ってくれたコードをコピーしましょう。右上のアイコンをクリックするとコピーされます。

コピーした内容をセルにペーストしてください。

ペーストすると上記のようになります。
下記は実際のコードです。必要に応じてコピペしてください。
import pandas as pd
import matplotlib.pyplot as plt
from google.colab import drive
# Googleドライブをマウント
drive.mount('/content/drive')
# CSVファイルのパスを指定
file_path = '/content/drive/My Drive/Pythonによるデータ分析入門/初級編/000_データの読み込みとグラフ化/diabetes.csv'
# CSVファイルを読み込む
df = pd.read_csv(file_path)
# 列名Aのデータでヒストグラムを作成
# 'A'を実際の列名に置き換えてください。
# diabetes.csv には 'A' という列名はないので、適切な列名に置き換えてください。
# 例えば、'Glucose' 列のヒストグラムを作成する場合は、以下のように変更します。
plt.hist(df['Glucose'], bins=10)
plt.xlabel('Glucose') # x軸ラベルを変更
plt.ylabel('Frequency')
plt.title('Histogram of Glucose') # タイトルを変更
plt.show()セルを実行してください。
するとしっかりとヒストグラムが表示されます。
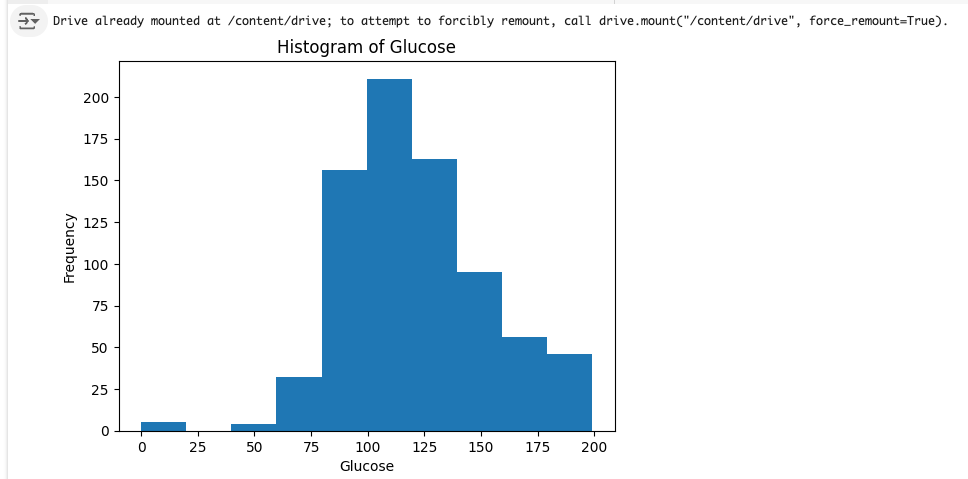
自分でコードを書かずにデータの読み込みとグラフ化ができましたね
どうやってもグラフが表示されない!!という人は、以下を確認してください。
「ダウンロードしたつもりになっている」パターンですね。以下のコードで、csvファイルの有無を確認しましょう。
from google.colab import drive
import os
# Googleドライブのマウント
drive.mount('/content/drive')
def find_csv_files(root_dir): """ 再帰的にディレクトリを走査し、.csvファイルのパスをリストで返す関数。 Args: root_dir: 走査を開始するルートディレクトリのパス。 Returns: .csvファイルのパスを含むリスト。 """ csv_files = [] for dirpath, dirnames, filenames in os.walk(root_dir): for filename in filenames: if filename.endswith('.csv'): csv_files.append(os.path.join(dirpath, filename)) return csv_files
# マイドライブのルートディレクトリ
my_drive_root = '/content/drive/MyDrive'
# .csvファイルのパスを取得
csv_file_paths = find_csv_files(my_drive_root)
# .csvファイルのパスを表示
if csv_file_paths: print("csvファイルが見つかりました:") for file_path in csv_file_paths: print(file_path)
else: print("マイドライブにcsvファイルは見つかりませんでした。")「マイドライブにcsvファイルは見つかりませんでした」と表示される方は、そもそもGoogle Drive内にcsvファイルが存在していません。チェックポイント1に戻ってください。
またよくあるのが、アカウントが異なっているパターンです。
お使いのGoogleドライブと、Google Colabのアカウトは一致していますか?
画面右上のアイコンを確認してくださいね。

FileNotFoundErrorを修正できないときは、フォルダの階層構造が間違っていたり、余計な半角スペースが入っていたりします。
上記の「csvファイルが存在しているのか」のコードを実行すると、csvファイルのファイルパスが表示されます。
このファイルパスが正しいものです。自分が思う「こういうファイルパスのはずだ」と認識がズレているかもしれません。正しい方を使って、以下のようにコードを修正してください。
# CSVファイルのパスを指定
# 正しいファイルパスに修正してください。
file_path = '/content/drive/My Drive/Pythonによるデータ分析入門/初級編/000_データの読み込みとグラフ化/diabetes.csv'「自分が思っていたパスと違っていた」という場合は、チェックポイント1に戻って、コードを実行すると本記事と同じフォルダ構造を作成することができます。
plt.hist(df['Glucose'], bins=10)
plt.xlabel('Glucose') # x軸ラベルを変更上記のようにdf['Glucose']と修正してください。df['xxx']のxxxの部分に存在しない列名を入力するとKeyErrorが発生しますので、スペルミスがないように修正してください。
長くなりましたが、手順は単純です。
エクセルのデータをcsv形式にして、Google Colabで読み込み、グラフ化したということです。
生成AIに手伝ってもらったので、「コードの意味を理解する」というところまでは到達していませんが、「使う」ことはできましたね。
ここから少しずつ理解を深めていきましょう。
また、本記事で使用したコードは以下からダウンロードできます。
新しいデータを用意しましたので、以下からダウンロードしてください。
はじめからcsv形式にしてあるので、ご自身のGoogle Driveにアップロードするところからはじめてください。
データの詳細は以下のサイトを参照してください。
プロンプトを変えてみるとどんなコードが生成されるのかも試してみてください。
グラフにも色々な種類があります。今回は度数分布(ヒストグラム)を作成しましたが、散布図などもあるので試してみてくださいね。
