 meducode
meducode

本記事は、以下の記事の続編です。設定等は以下の記事を踏襲します。
 分類モデルを使って診断AIを作ろう
分類モデルを使って診断AIを作ろう 以下のデータセットを使用します。
Google Colabでのcsvファイルの読み込み等は以下の記事を参考にしてください。
 Pythonでエクセルファイルを読み込んでグラフ化しよう
Pythonでエクセルファイルを読み込んでグラフ化しよう 基本となるGoogle Colabのノートブックは以下からダウンロードできます。

これまでの演習は、目的変数である「糖尿病か否か」に対して、「妊娠回数」や「血糖値」などの説明変数があり、それらを「丸ごとAIに突っ込んだ」感じでしたね。
今回は、目的変数と説明変数の関係性を解析してみましょう。

アウトカムと予測因子の関係性を明示しましょう
決定木は、データを特徴量に基づいて分割し、ツリー構造で予測を行うシンプルなモデルです。
各ノードでデータを条件によって分割し、最終的な葉(リーフ)ノードで予測結果を出します。

まずは結果を見た方が早いかもしれません。
以下のプロンプトで、Colab上にコードを生成します。
このデータ(file_path)を使って、決定木モデルを作成してください。
なお目的変数は、diabetes.csvのoutcome列であり、糖尿病と診断されたか否かを表しています。糖尿病の場合は1、健全であれば0というカテゴリー変数が使われています。
本モデルは、その他の説明変数を使って、目的変数を予測する2クラス分類タスクです。
決定木モデルを訓練後に、どの説明変数がどの程度寄与するのか可視化してください。
また決定木を可視化する際は、各項目が見えるように拡大縮小できるようにしてください。
生成されたコードは以下のとおりです。
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.tree import plot_tree
import matplotlib.pyplot as plt
# Googleドライブをマウント
# (すでにマウントされている場合は不要)
# from google.colab import drive
# drive.mount('/content/drive')
# CSVファイルのパスを指定
file_path = '/content/drive/My Drive/Pythonによるデータ分析入門/初級編/000_データの読み込みとグラフ化/diabetes.csv'
# CSVファイルを読み込む
df = pd.read_csv(file_path)
# 説明変数と目的変数を指定
X = df.drop('Outcome', axis=1)
y = df['Outcome']
# データを訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 決定木モデルを作成
model = DecisionTreeClassifier(max_depth=3, random_state=42) # max_depthは木の深さを制限
# モデルを訓練
model.fit(X_train, y_train)
# 決定木の可視化
plt.figure(figsize=(20, 10)) # 図のサイズを大きくする
plot_tree(model, feature_names=X.columns, class_names=['0', '1'], filled=True)
plt.show()
# 特徴量の重要度を表示
feature_importance = pd.DataFrame({'feature': X.columns, 'importance': model.feature_importances_})
print(feature_importance.sort_values('importance', ascending=False))そして得られた決定木が以下のとおりです。

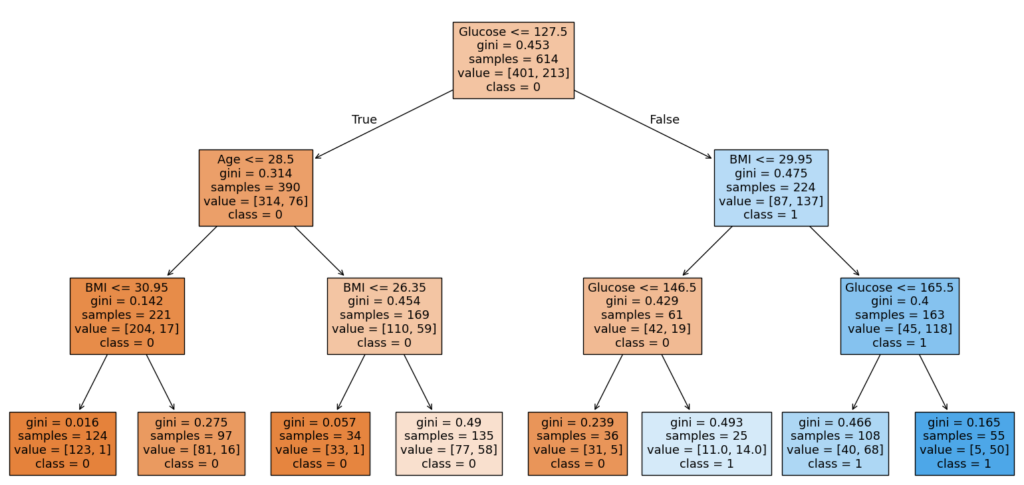
ちょっと図が小さくて見えないかもしれませんが、一番上の四角には「Glucose <= 127.5」と書いてあります。
「血糖値が127.5以下の場合」という意味ですね。

これは「127.5を閾値にするとうまく説明できる」という意味だと考えてください。
gini = 0.453 とあります。これはジニ不純度と呼ばれる指標で、2クラス分類の場合0から0.5の間の数値になります。
0に近いほど良いと考えてください。ジニ不純度が0に近いほど、クラス(糖尿病か健全か)のばらつきが少ないことを表しています。
0.453は高いばらつき度合いと言えます。つまり「血糖値127.5を閾値にすると良いものの、あんまり役には立たないよ」という意味に解釈できます。
sample = 614とあります。これはそのままサンプル数ですね。
全データは768件ありますが、AIの学習にはその80%を使ったので、614件になっています。
value = [401, 213]は、クラス分布を表しています。
クラス0(健全クラス)は401件、クラス1(糖尿病クラス)は213件という意味です。
class = 0は、614件のデータのうち最も多く分類されたクラスを表しています。つまり健全クラスですね。
ランダムフォレストは、多数の決定木を組み合わせたアンサンブル学習アルゴリズムです。
各決定木は異なる特徴量やデータサンプルを用いて訓練され、その結果を多数決(分類の場合)や平均(回帰の場合)で統合します。
ランダムフォレスト(RF)は、複数の決定木からなっています。
そのため決定木のようにツリー構造での可視化はできません(1つ分の決定木の可視化はできます)。
そのため「特徴量の重要度(Feature Importance)」で図示します。
ランダムフォレストのコードは以下のとおりです。
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
# ランダムフォレストモデルを作成
model = RandomForestClassifier(n_estimators=100, random_state=42)
# モデルを訓練
model.fit(X_train, y_train)
# テストデータで予測
y_pred = model.predict(X_test)
# 正解率を計算
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
# 特徴量の重要度を表示
feature_importance = pd.DataFrame({'feature': X.columns, 'importance': model.feature_importances_})
print(feature_importance.sort_values('importance', ascending=False))
# 可視化 (特徴量の重要度を棒グラフで表示)
plt.figure(figsize=(10, 6))
plt.barh(feature_importance['feature'], feature_importance['importance'])
plt.xlabel('Importance')
plt.ylabel('Feature')
plt.title('Feature Importance of Random Forest')
plt.show()結果は以下のとおりです。
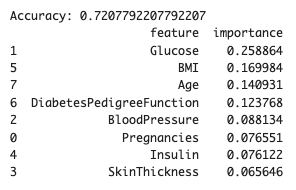
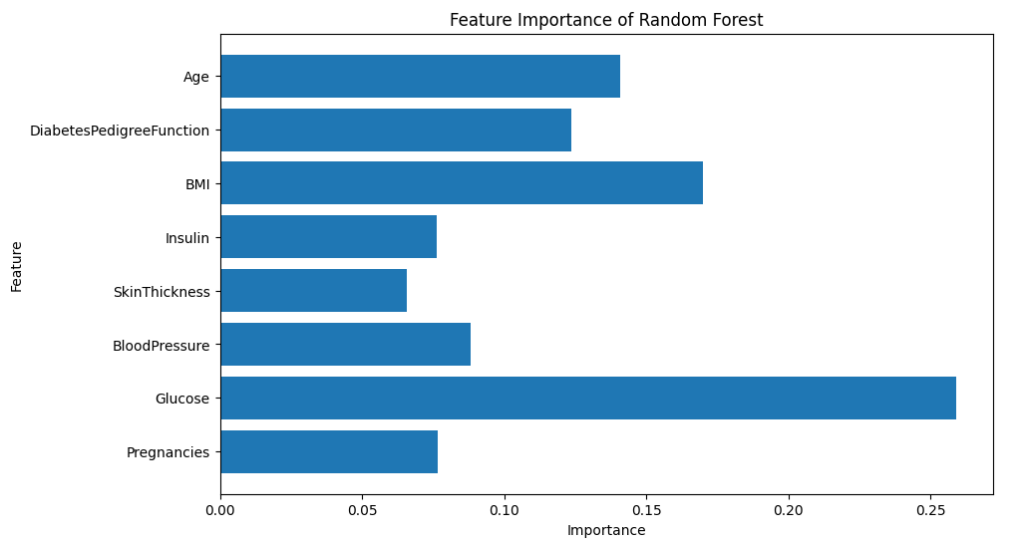
血糖値が高い重要度を示していますが、決定木のときほどではありませんね。
勾配ブースティングは、複数の弱学習器(通常は浅い決定木)を順番に作成し、それぞれのモデルが前回までの誤差(残差)を補正する形で訓練されるアンサンブル学習手法です。
つまり1つの決定木の間違い(誤差)を正すように、次の新しい決定木が学習されていくイメージです。
勾配ブースティングモデルの実装は以下のとおりです。
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.metrics import accuracy_score
# 説明変数と目的変数を指定
X = df.drop('Outcome', axis=1)
y = df['Outcome']
# データを訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 勾配ブースティングモデルを作成
model = GradientBoostingClassifier(n_estimators=100, random_state=42)
# モデルを訓練
model.fit(X_train, y_train)
# テストデータで予測
y_pred = model.predict(X_test)
# 正解率を計算
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
# 特徴量の重要度を表示
feature_importance = pd.DataFrame({'feature': X.columns, 'importance': model.feature_importances_})
print(feature_importance.sort_values('importance', ascending=False))
# 可視化 (特徴量の重要度を棒グラフで表示)
plt.figure(figsize=(10, 6))
plt.barh(feature_importance['feature'], feature_importance['importance'])
plt.xlabel('Importance')
plt.ylabel('Feature')
plt.title('Feature Importance of Gradient Boosting')
plt.show()勾配ブースティングの結果は以下のとおりです。
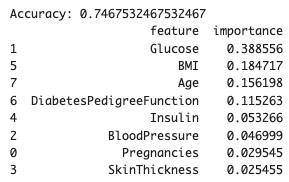
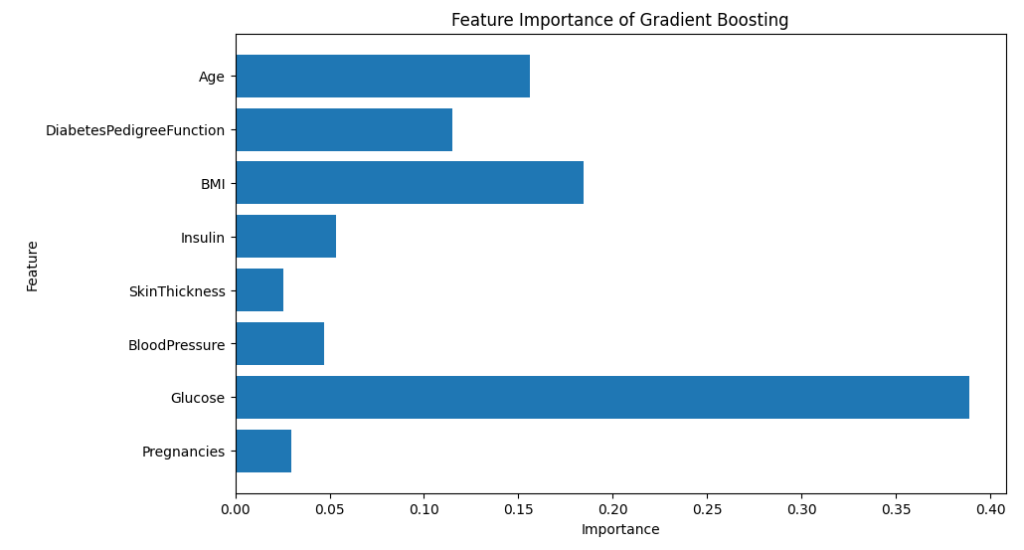

ランダムフォレストと大差ない感じがしますね
XGBoostは勾配ブースティングアルゴリズムの改良版で、高速かつ効率的な実装です。
勾配ブースティングと同様に弱学習器(通常は決定木)を組み合わせて誤差を修正していきますが、計算効率や精度向上のためにさまざまな技術的工夫が施されています。
XGBoostの実装コードは以下のとおりです。
# XGBoostのライブラリをインポート
from xgboost import XGBClassifier
# 説明変数と目的変数を指定
X = df.drop('Outcome', axis=1)
y = df['Outcome']
# データを訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# XGBoostモデルを作成
model = XGBClassifier(random_state=42)
# モデルを訓練
model.fit(X_train, y_train)
# テストデータで予測
y_pred = model.predict(X_test)
# 正解率を計算
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
# 特徴量の重要度を表示
feature_importance = pd.DataFrame({'feature': X.columns, 'importance': model.feature_importances_})
print(feature_importance.sort_values('importance', ascending=False))
# 可視化 (特徴量の重要度を棒グラフで表示)
plt.figure(figsize=(10, 6))
plt.barh(feature_importance['feature'], feature_importance['importance'])
plt.xlabel('Importance')
plt.ylabel('Feature')
plt.title('Feature Importance of XGBoost')
plt.show()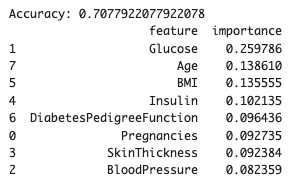
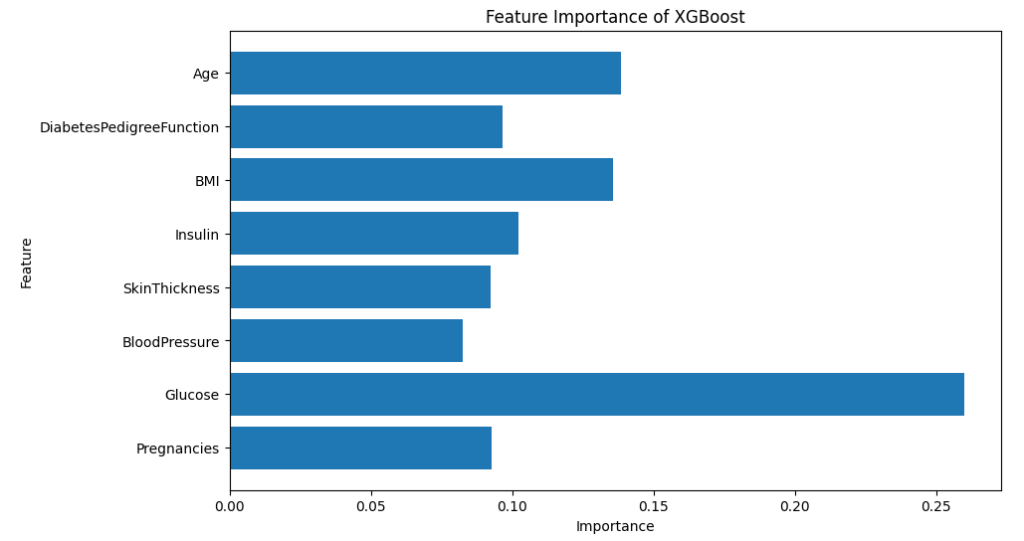
血糖値が重要であることはこれまでと同様ですね。
Accuracy: 0.708
- Glucose: 0.597
- BMI: 0.262
- Age: 0.140
Accuracy: 0.721
- Glucose: 0.259
- BMI: 0.170
- Age: 0141
- DiabetesPedigreeFunction: 0.124
- BloodPressure: 0.088
Accuracy: 0.747
- Glucose: 0.389
- BMI: 0.170
- Age: 0141
- DiabetesPedigreeFunction: 0.124
- BloodPressure: 0.088
Accuracy: 0.708
- Glucose: 0.260
- Age: 0.139
- BMI: 0.136
- Insulin: 0.102
- DiabetesPedigreeFunction: 0.096

私の結果は以上です
4つのモデルで分類タスクを解いた結果、正解率は70~75%程度でした。
また全てのモデルで重要とされた上位3つは、Glucose, Age, BMI でした。
今回使ったGoogle Colabの実装コードは以下からダウンロードできます。
今回は平均して72%程度の分類精度でした。
ちなみに下記の論文では、97.833%の分類精度を達成しています。
一体どうやったんでしょう?
忘れてはいけないのが、モデルの精度はデータセットを使って計算されていることです。
別の言い方をすると、精度の高いモデルは「そのデータセット(現象)をよく説明できている」といえます。
しかし、このことが新しいデータをよく説明できることと一致するわけではありません。
ややこしいですね。
つまり「精度は手元のデータで計算された指標」に過ぎず、「現実世界で役に立つ」ことを保証する指標ではないのです。
新しいデータ(現実世界のデータ)が学習データと似ているときには、モデルは新しいデータでも良い精度を達成できます。この「データが似ている」ことを「データの分布が近い」と表現します。

現実的に役立つモデルは、現実的なデータ分布で学習したモデルということですね
上記のような理由で、AI開発をする際には「より多くの、より多様な」データで学習したいわけです。
今回は、説明変数と目的変数の関係性を明示するために決定木系のモデルを試してみました。
なかなか高い正解率は達成できませんでしたが、血糖値、年齢、BMIが重要な因子であることが示唆されました。
モデルの精度を向上させることももちろん重要です。
しかし今回の結果を踏まえて、糖尿病のメカニズムにおいて、血糖値・年齢・BMIが何なのかを考察することも現実的なアプローチですね。