 meducode
meducode

分類モデルとは、出力結果が「良性か悪性か」、「健康か病気か」などいくつかのカテゴリーになるモデルです。
「ある疾患に罹患しているか否か」という判断ができるのでAIによる診断にはぴったりです。
「良性と悪性」など、区切って分けられることを「離散的(discrete)」といいます。
なお離散的の反対は「連続的(continuous)」です。
そして離散的な量(癌のステージなど)を「離散量(digital)」といい、連続量(体重など)を「アナログ(analog, analogue)」といいます。
今回は、下記の記事の続きです。
下記の内容を受講済みの方は新たにデータのダウンロード等は不要です。
 Pythonでエクセルファイルを読み込んでグラフ化しよう
Pythonでエクセルファイルを読み込んでグラフ化しよう 上記の記事を受講していない場合は、新たにデータのダウンロードからお願いします。
こちらからデータをダウンロードしてください。
またGoogle Colabを利用します。
Google Colabの設定、csvファイルの読み込み等は以下の記事を参照してください。
 Google DriveとGoogle Colabを準備しよう
Google DriveとGoogle Colabを準備しよう 本記事で使用したコードは以下からダウンロードできます。
基本的には手順を一緒に進めることをおすすめしますが、あらかじめコードを読みたい方はこちらからダウンロードしてください。

データに含まれている項目は以下のとおりです。
Pregnancies:妊娠回数。妊娠回数が増えると、妊娠糖尿病のリスクが上昇します。
Glucose:経口ブドウ糖負荷試験(Oral Glucose Tolerance Test, OGTT)から2時間後の血漿中のグルコース濃度。OGTT
から2時間も経つと、健常者ではグルコース濃度は下がっています。
BloodPressure:血圧。高血圧と糖尿病には相関があります。
SkinThickness:皮膚の厚さ。皮下脂肪の量を示し、体脂肪率との相関を示します。
Insulin:OGTTから2時間後の血清インスリン濃度。インスリン抵抗性があると血糖値が高いまま維持されます。
BMI:Body Mass Index. 肥満傾向かどうかの指標です。
DiabetesPedgreeFunction:糖尿病血糖要因、糖尿病家系機能。糖尿病の家族歴と遺伝的要因を数値化した指標です。
Age:年齢。加齢に伴いインスリン分泌量が減少します。
Outcome:結果。糖尿病と診断されれば1, 健全であれば0が割り当てられます。
これらの検査項目の結果が、768名分あります。
使用するデータには、Outcome(結果)という列があります。データを見ると0か1が入力されています。
これが「糖尿病と診断されたか否か」を表しています。健全であれば0、糖尿病であれば1です。
このように、ある種の分類を示す数をカテゴリー変数(categorical variable)といいます。
例えばコインの表を0、裏を1などと表現します。
ただの割り当て用の数字なので、この数字で計算することに意味はありません。
今回作る診断AIモデルは、この診断結果を出力するわけですね。
診断結果に対応するのが、血糖値だったり、年齢だったりですね。
説明変数(explanatory variable)、特徴量(feature variable)と総称されます。
【対応する値の表現方法】
従属変数 dependent variable : 独立変数 independent variable
結果 Outcome : 予測因子 Predictor
標的変数 target variable : 特徴 feature
応答変数 response variable : 説明変数 explanatory variable

分野ごとに使われ方が違う感じです
まとめると「診断結果に対する根拠となる数値」と「診断結果そのもの」があるということです。
下記の記事を受講済みの方は、000_import-data.ipynbをそのまま利用できます。
Pythonでエクセルファイルを読み込んでグラフ化しよう 上記の記事を受講していない場合は、以下からノートブックをダウンロードしてください。
000_import-data.ipynbのページが開かれます。
ただし見えているのは私(管理者)のノートブックです。
自分用に保存するため「ファイル > ドライブにコピーを保存」を選択してください。これであなたのGoogleドライブにこのノートブックが保存されます。
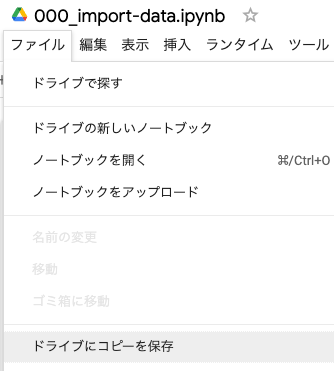
自分のGoogleドライブにノートブックを保存しないと、編集はできません。
AIを学習させる上で、GPU(Graphic Processing Unit)の利用は必須です。
Google Colabでは無料でGPUを使用することができます(ある程度の制限付きですが)。
「ランタイム > ランタイムのタイプを変更」を選択してください。
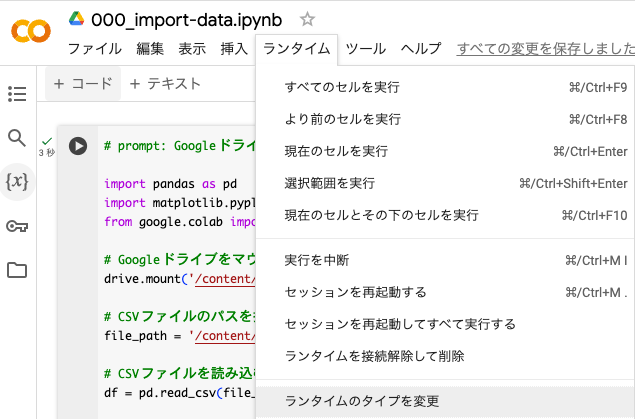
ポップアップが表示されるので「T4 GPU」を選択してください。
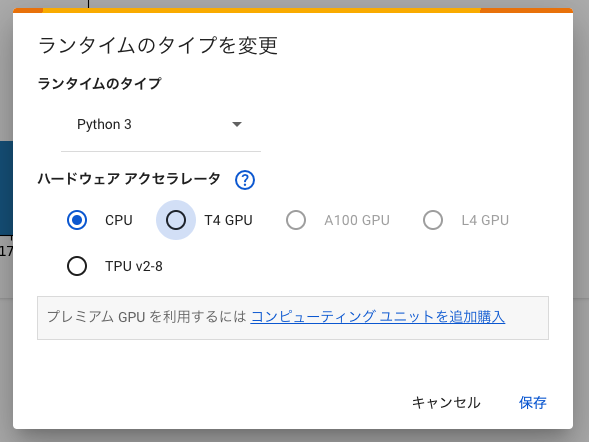
「ランタイムを接続解除して削除」という警告文が表示されますが「OK」で進めてください。
少し時間はかかりますが、ランタイムが変更されます(画面自体は変わりません)。
成功すると画面右上の部分に「T4」と表示されます。
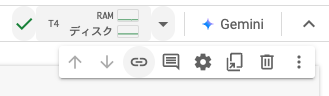
Google Colabの準備が整ったら、コーディングを始めましょう。
すでにセルが1つあり、ヒストグラムが表示されていると思います。
セルを追加しましょう。セルの境界部にカーソルを持っていくと「+ コード」と「+ テキスト」と表示されます。「+ コード」を押してください。
わかりにくかったら、左上のメニューにも「+ コード」があるのでここを押してください。

すると新しいセルが追加されます。
「生成」をクリックして、以下のプロンプトを入力してください(コピペしてください)。
はじめにGoogleドライブへのマウントを行ってください。
つぎに、’/content/drive/My Drive/Pythonによるデータ分析入門/初級編/000_データの読み込みとグラフ化/diabetes.csv’ にあるcsvファイルを使って、分類モデルを作成してください。
なお、列名’Outcome’ が目的変数であり、糖尿病と診断された場合は1、健康な場合は0というカテゴリー変数が割り当てられています。
その他の列を説明変数として、Outcome列の値を予測する2クラス分類モデルを作成してください。
また、エポック数を横軸、学習データの損失と訓練データの損失を縦軸にとるグラフを図示してください。
同じように、エポック数を横軸、学習データの精度と訓練データの精度を縦軸にとるグラフも図示してください。
生成結果は、毎回一致するわけではないので、私の結果を以下に載せておきます。
下記のコードは長いですけど、「ふーん」くらいで流し見してください。
また自分のコードのエラーがどうしても解消されないときは、以下のコードをコピペして使ってください。
# prompt: '/content/drive/My Drive/Pythonによるデータ分析入門/初級編/000_データの読み込みとグラフ化/diabetes.csv' にあるcsvファイルを使って、分類モデルを作成してください。
# Googleドライブへのマウントも行ってください。
# なお列名'Outcome' が目的変数であり、糖尿病と診断された場合は1、健康な場合は0というカテゴリー変数が割り当てられています。
# その他の列を説明変数として、Outcome列の値を予測する2クラス分類モデルを作成してください。
# また、エポック数を横軸、学習データの損失と訓練データの損失を縦軸にとるグラフを図示してください。
# 同じように、エポック数を横軸、学習データの精度と訓練データの精度を縦軸にとるグラフも図示してください。
import pandas as pd
import matplotlib.pyplot as plt
from google.colab import drive
from sklearn.model_selection import train_test_split
from tensorflow import keras
from tensorflow.keras import layers
# Googleドライブをマウント
drive.mount('/content/drive')
# CSVファイルのパスを指定
file_path = '/content/drive/My Drive/Pythonによるデータ分析入門/初級編/000_データの読み込みとグラフ化/diabetes.csv'
# CSVファイルを読み込む
df = pd.read_csv(file_path)
# 説明変数と目的変数を分ける
X = df.drop('Outcome', axis=1)
y = df['Outcome']
# データを訓練データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# モデルを構築
model = keras.Sequential([ layers.Dense(128, activation='relu', input_shape=(X_train.shape[1],)), layers.Dense(64, activation='relu'), layers.Dense(1, activation='sigmoid')
])
# モデルをコンパイル
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# モデルを訓練
history = model.fit(X_train, y_train, epochs=50, batch_size=32, validation_data=(X_test, y_test))
# 学習データの損失と訓練データの損失をプロット
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.legend()
plt.show()
# 学習データの精度と訓練データの精度をプロット
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.show()上記のコードを実行すると、ずらずらーっと文字が表示されるはずです。

これが「AIが学習中の様子」です。
もう少し待つと学習が止まって、グラフが表示されます。
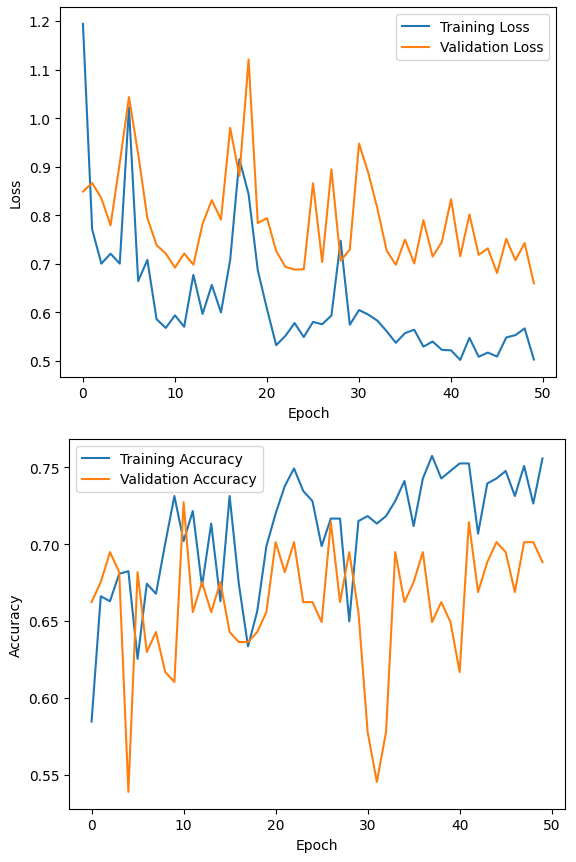
まだ詳しくは説明しませんが、Loss(損失値)は小さい方が良く、Accuracy(正解率)は大きい方が良い指標です。
横軸は学習回数を表しています。今回は、訓練データを50周(エポック)しています。
数値が上下していますが、大まかに言えば、Lossは学習するほどだんだん小さくなり、Accuracyはだんだん大きくなるということがわかりますね。
青は訓練データ、オレンジは検証データを表しています。

これで診断AIの完成です。
簡単すぎて何が起こっているのかわからないですね。
先ほどの結果を見ると、もっと学習させれば結果が良くなりそうですね。
学習回数を増やすようにコードを修正しましょう。
history = model.fit(X_train, y_train, epochs=50, batch_size=32, validation_data=(X_test, y_test))というところを探してください。
そしてepochs=50のところをepochs=200に修正してください。

すると結果は以下のようになります。
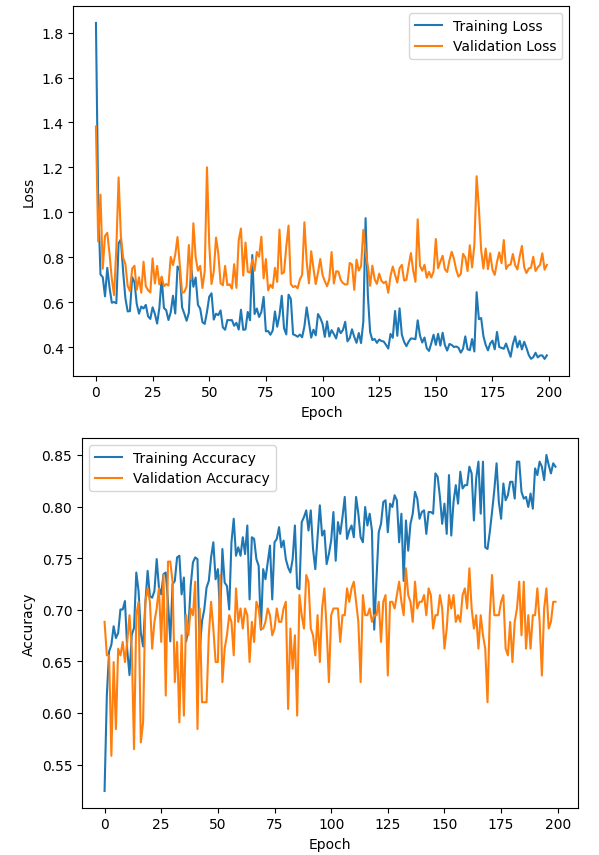
重要なのはValidationの方です。オレンジの方を見てください。
するとLossは下がっていかず、Accuracyも上がっていかない様子が見て取れます。
つまり「学習回数を増やしても結果が良くなっていない」ことがわかります。
ここからが人間の出番ですね。
「なんでこうなったの?」と考えて仮説を立て、検証していきます。
気になる方もいると思うので、もっと学習回数を増やしてみました。
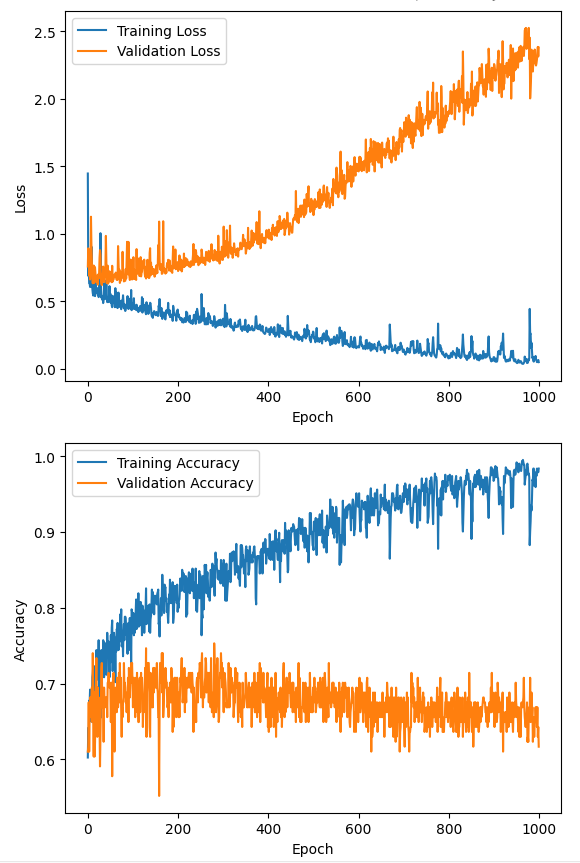
Validation Loss は増加傾向、Validation Accuracy は0.65あたりでプラトーという感じですね。
つまり学習回数を増やしても、予測精度は上がらず、間違え方もひどくなっている状態です。
プラトー(plateau)とは
地学用語で高原や台地を意味します。
これを転用して、グラフ上で見て数値が変わらない・一定であることをプラトーと表現します。
訓練データでの損失値(Training Loss)は減少しているのに、検証データでの損失値(Validation Loss)は増加していく現象を過学習(Overfitting)といいます。

このグラフは、わかりやすい過学習の見本ですね。

結局これ何なん?という感想ですよね
「これがAIなの?」、「一体何やってんの?」と思っているかと思います。
ここまではdiabetes.csvファイルの説明変数のパータンを学習して、糖尿病かを診断するAIを作成しています。
しかし実際には「作ったあとに何をするの?」ということが大事ですよね。
AIモデルを作る目的は、「まだ手元にない新しいデータを入力」して診断することです。
ここまでは単に「既存データのパータンを学習させた」だけです。次は「これを使いましょう」というステップに移ります。
作ったモデルの利用方法は単純です。
新しい患者データをモデルに入力して、糖尿病かどうかの診断をさせるのです。
新しいデータを入力すれば、モデルは糖尿病か否かを出力します。
しかしその診断が実際に正しいかどうかは不明です。
そして診断結果の責任は、日本の医師/歯科医師法上、医師あるいは歯科医師が負うことになっています。
diabetes.csvには、診断結果(Outcome)が含まれていますが、新しいデータには当然ありません。
そのためAIの診断結果を受けて「AIの診断をどう評価するか」という人間側の判断という新しいステップが生じるのです。
以下のプロンプトで新規データを生成し、その診断結果も表示してもらいました。
ここまでに作成したモデル(modelインスタンス)を使って、模擬データに対する予測(診断)を行ってください。
模擬データは、学習に使用した’/content/drive/My Drive/Pythonによるデータ分析入門/初級編/000_データの読み込みとグラフ化/diabetes.csv’ のデータを参考にして、新たに作成してください。
まずは5名分の模擬データを作ってください。
そして各人のデータを表示し、その人の診断結果もわかりやすく表示させてください。
生成されたコードは以下のとおりです。
import pandas as pd
import numpy as np
# 模擬データを作成
mock_data = { 'Pregnancies': [6, 1, 8, 1, 0], 'Glucose': [148, 85, 183, 89, 137], 'BloodPressure': [72, 66, 64, 66, 40], 'SkinThickness': [35, 29, 0, 23, 35], 'Insulin': [0, 0, 0, 94, 168], 'BMI': [33.6, 26.6, 23.3, 28.1, 43.1], 'DiabetesPedigreeFunction': [0.627, 0.351, 0.672, 0.167, 2.288], 'Age': [50, 31, 32, 21, 33]
}
mock_df = pd.DataFrame(mock_data)
# 予測を行う
predictions = model.predict(mock_df)
# 結果を表示
for i in range(len(mock_df)): print(f"--- Person {i+1} ---") print(mock_df.iloc[i]) if predictions[i][0] > 0.5: print("Diagnosis: Diabetes") else: print("Diagnosis: No Diabetes") print("-" * 20) 実行結果は以下のとおりです。
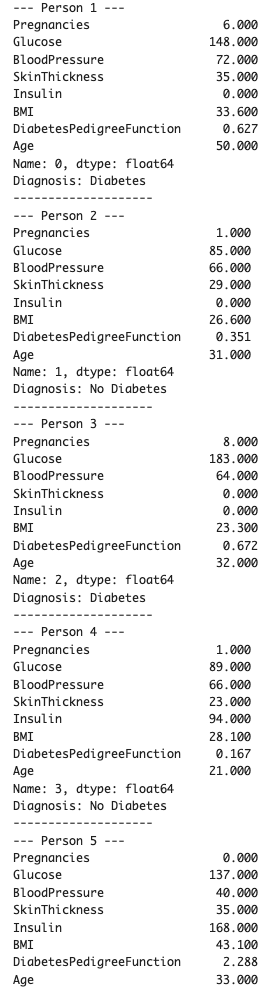
Person 1~5の模擬データが作られて、それぞれ診断されましたね。
このように既存(過去)のデータからAIモデルを作成し、新規(未来)のデータを入力するのが、医療AIの活用方法です。
ここまで実行したコードを以下からダウンロードできます。
「なぜか自分のコードが動かない」というような場合にご活用ください。
今回は、diabetes.csvを使って糖尿病診断AIを開発しました。
生成AIを使うことで、それほど苦労することなく分類AIモデルを作成できたと思います。
また「過学習」という重要な概念も登場しました。

AIって簡単に作れるんだ、と思っていただければ幸いです
